Distribution 별 수리 통계학을 정리의 첫 번째는 Bernoulli distribution 이다.
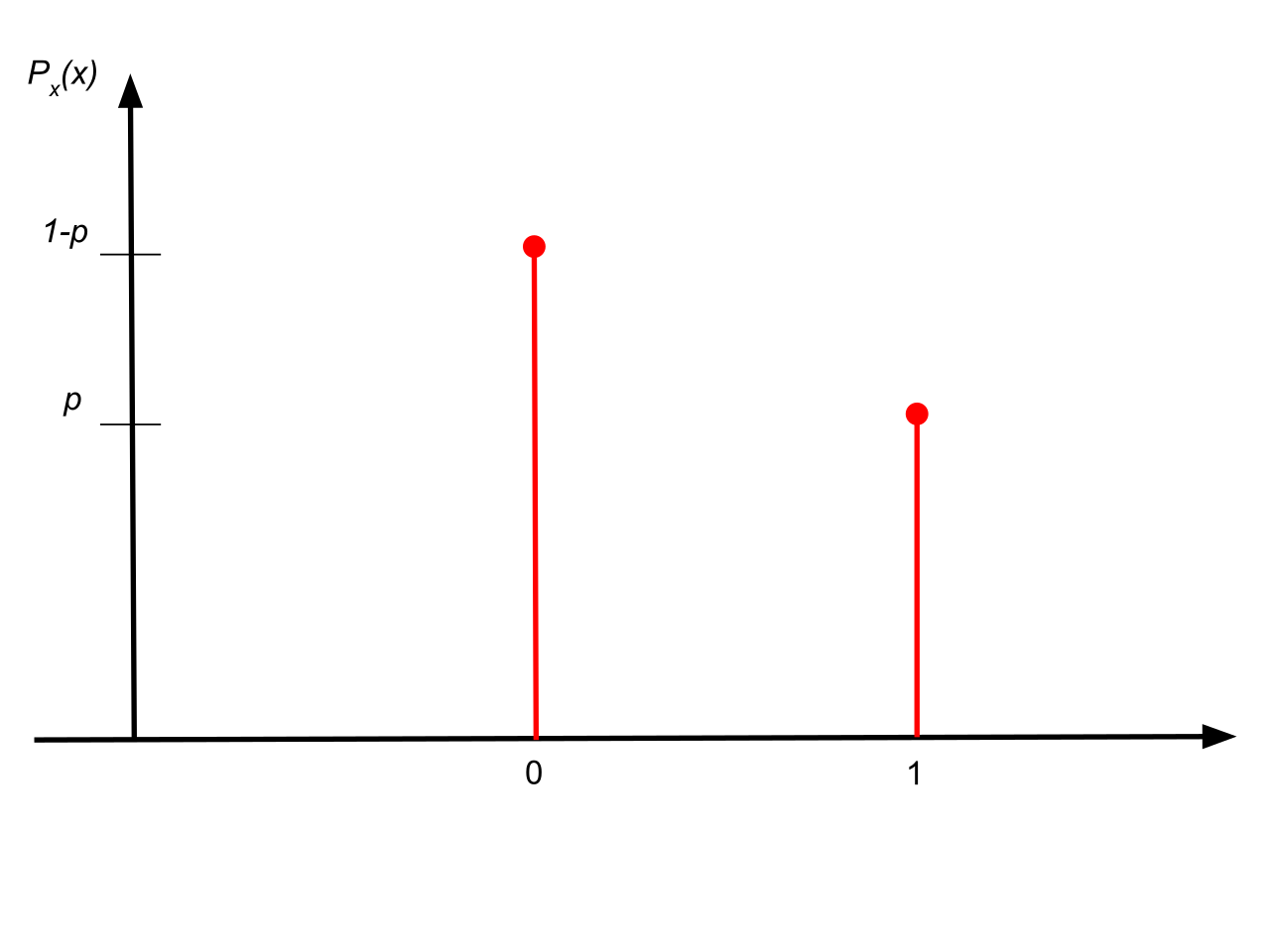
베르누이 분포는 동전의 앞, 뒤처럼 오직 두 가지 범주만 가진 이산형 확률분포이다.
예를 들어, 시험을 봤을 때 60점 이상이면 합격, 미만이면 불합격이라 하자.
- 60점 이상 = 합격 ⇨ 이를 1이라 하고, 합격할 확률을 P(X=1) 로 표기할 수 있다.
- 60점 미만 = 불합격 ⇨ 이를 0이라 하고, 불합격할 확률을 P(X=0) 로 표기할 수 있다.
❗베르누이 분포의 확률질량함수 𝒇(𝒙)는 다음과 같다.
$$ f(x)=P(X=x)=p^{x}(1-p)^{1-x}, x=0,1 $$
❗베르누이 분포를 따르는 확률변수의 기댓값 E(X)=p, 분산 Var(X)=p(1-p) 이다.
❗베르누이 분포의 적률생성함수는 다음과 같다.
$$ M(t)=E(e^{tX})=(1-p)+pe^{t} $$
위 적률생성함수를 증명해보자.
베르누이분포는 이산형 확률분포이므로, 베르누이분포를 따르는 확률변수 X의 적률생성함수는 다음과 같이 정의된다.
$$ M_{X}(t)=E(e^{tX})=\sum_{x=0}^{\infty}e^{tx}f(x)=\sum_{x=0}^{\infty}e^{tx}p^{x}(1-p)^{1-x} $$
𝒙는 오로지 0과 1이므로, 이를 위에 대입하면,
$$ M_{X}(t)=\sum_{x=0}^{\infty}e^{tx}p^{x}(1-p)^{1-x}=e^{0}p^{0}(1-p)^{1} + e^{t}p^{1}(1-p)^{0}=(1-p)+pe^{t} $$
따라서 베르누이분포의 적률생성함수는 다음과 같다.
$$ M_{X}(t)=(1-p)+pe^{t} $$
✏이번에는 베르누이분포의 가능도함수, 로그가능도함수를 살펴본 후 최대가능도추정량을 구해보도록 하겠다.
❗먼저 가능도함수를 구해보자.
$$ L(\theta)=\prod_{i=1}^{n}f(x_{i}|\theta)=\prod_{i=1}^{n}p^{x_{i}}(1-p)^{1-x_{i}}=p^{\sum_{i=1}^{n}x_{i}}(1-p)^{n-\sum_{i=1}^{n}x_{i}} $$
❗이 가능도함수에 로그를 취한 함수를 로그가능도함수라 하는데, 이를 구해보자.
가능도함수에 로그를 취하면 다음과 같고,
$$ logL(\theta)=log(p^{\sum_{i=1}^{n}x_{i}}(1-p)^{n-\sum_{i=1}^{n}x_{i}}) $$
이는 다음과 같이 풀이할 수 있다.
$$ logL(\theta)=\sum_{i=1}^{n}x_{i} logp + (n-\sum_{i=1}^{n}x_{i}) log(1-p) $$
가능도함수 L(θ|𝑥)는 확률표본에서 얻을 수 있는 모수의 모든 정보를 가지고 있다.
따라서 이를 바탕으로 모수에 대한 가능성이 가장 높은 통계량을 찾는 것을 고려할 수 있다.
모수 θ에 대해 가능도함수 L(θ|𝑥)를 최대로 하는 통계량을 최대가능도추정량이라 한다.
❗최대가능도추정량은 로그가능도함수에 대해 미분하여 0을 만족하는 hat(θ)이다.
위에서 로그가능도 함수를 모수인 p에 대해 미분하여 0으로 놓으면 다음과 같다.
$$ \frac{d}{dp}logL(p)=\frac{\sum_{i=1}^{n}x_{i}}{p} - \frac{n-\sum_{i=1}^{n}x_{i}}{1-p}=0 $$
이를 풀면
$$ \frac{(1-p)\sum_{i=1}^{n}x_{i}-p(n-\sum_{i=1}^{n}x_{i})}{p(1-p)}=\frac{\sum_{i=1}^{n}x_{i}-np}{p(1-p)}= 0 $$
가 되고, 이를 만족하기 위해서는
$$ \sum_{i=1}^{n}x_{i}=np $$
이므로, 따라서 최대가능도추정량은
$$ \widehat{p}= \frac{1}{n} \sum_{i=1}^{n}x_{i} $$
한 가지 더, 로그가능도함수를 두 번 미분하면 0보다 작은 값이 되므로 hat(p)에서 가능도함수의 최댓값을 얻을 수 있다.
'STATISTICS' 카테고리의 다른 글
| 수리통계학 - 이항분포 (Bionomial distribution) (0) | 2022.10.08 |
|---|---|
| 통계 : Dummy Variable Trap (1) | 2022.10.08 |
| Which diagnostic test is better? 진단 검사 비교 (1) | 2022.10.06 |
| GLM의 모형진단 - GLM part. 4 (1) | 2022.10.06 |
| GLM에서 설명변수에 대한 검정 - GLM part. 3 (1) | 2022.10.06 |



