이와 같이 25개 종류의 과자들을 샘플로 선택하였고, 평균을 구해보니 17.16g 이었다.
그럼, 이 때 귀무가설과 대립가설은 다음과 같다.
H0:¯X=15
H1:notH0
이를 검정하기 위해서는 대표적인 parametric test (모수검정)인 one-sample t-test를 시행할 수 있다.
혹은 wilconxon signed-rank test와 같은 비모수 검정법을 이용 할 수 있다.
그럼 우리 예시를 검정하기 위해 어떤 test를 사용하면 좋을까?
1. 정규성 검정 후 검정법 선택
많은 통계 교과서 혹은 통계 강의에서 t-test 전에, 우선 샘플데이터들이 정규분포를 만족하는지 검정해야 한다고 서술한다.
이를 정규성 검정이라고 하는데, 정규성 검정의 대표적인 test는 shapiro-wilk's 검정이 있다.
만약 shapiro-wilk's 검정에서 p-value가 0.05보다 크면 정규성을 만족한다고 보고, 그대로 t-test를 진행하며, p-value가 0.05보다 작게 나오면 정규성을 만족하지 못하여 비모수 검정 선택을 거의 교과서적인(?) 정석으로 나타내는 경우가 많다.
뿐만 아니라 논문을 작성할 때, demographics 표에서 정규성 검정을 통과한 항목들은 평균과 표준편차로 작성, 정규성 검정을 통과하지 못한 항목들은 중앙값과 (최소값, 최대값) 혹은 중앙값과 (사분위수) 등으로 표현하기도 한다.
그러나 shapiro-wilk's 검정은 샘플사이즈의 영향을 크게 받기 때문에, 대략 히스토그램을 그린 후 해당 분포가 대략 정규분포를 따르는 것처럼 보이면 정규성을 만족한다고 보고 t-test를 시행할 수 있다.
2. 샘플사이즈 고려 후 검정법 선택
한편 또 다른 통계 교과서, 강의들에서는 정규성을 만족하는지 살펴볼 필요 없이 샘플 크기가 대략 30개 이상이면 바로 t-test를 진행해도 무방하다고 말하기도 한다. 중심극한정리에 따라 샘플 수가 커질수록 표본평균은 정규분포를 따르게 되므로 샘플크기가 크다면 굳이 정규성 검정을 할 필요 없이 바로 power가 더 높은 모수 검정 (parametric test) 을 진행해도 좋다는 입장이다.
다만, medical data는 그 특성 상 한쪽으로 치우친 (extrememly skewed data) 가 있는데, 그런 경우는 샘플사이즈가 25를 넘어도, outlier 때문에 non-parametric test를 사용하는 것이 권장된다.
📖자 그럼 우리의 경우 어떤 검정법을 사용하는 것이 좋을까?
① 우리 데이터의 샘플 사이즈는 25이다. 30개 이상은 아니지만, 그렇다고 엄청나게 적은 수의 샘플사이즈는 아니다.
-> 음.. 좀 애매하다. 데이터 분포를 살펴봐야겠다!
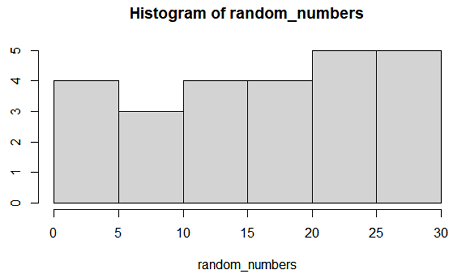
② 그럼 정규성 만족 여부를 살펴볼까? 앞서 말했듯이 shapiro-wilk's 검정보다는 히스토그램을 그려 정규성을 만족하는지 보는 것이 좋다. 우리 샘플 데이터의 히스토그램은 다음과 같다.
자, 위 히스토그램을 보고, 정규분포에 근사한다고 할 수 있을까?
-> 완전한 정규분포 모양은 아니지만.. 또 완전 치우친 분포도 아니고, outlier 값도 없는 것 같은데..
이런 경우가 제일 어렵다.
일단 최근 많은 통계논문들에서 t-test전 정규성 검정을 반드시 해야할 필요는 없다고 서술하고 있다.
Mixed effect model, 우리 말로는 혼합효과모형 (or 혼합모형) 이라는 것이 있다. 다른 말로는 Generalised Linear Mixed Model (=GLMM) 으로 표현되기도 한다.
처음 접할 때 매우 어렵다고 느껴지는 부분이기도 하고, 실제로도 어렵다. (나만 그럴수도..)
Mixed effect model 은 fixed effect (고정효과) 와 random effect (랜덤효과) 가 모두 고려된 모델인데, 고정효과는 보통 우리가 생각하는 일반적인 GLM의 설명변수들이다.
Fixed effect 는 보통 우리가 관심있어 하는 변수로, 종속변수와 어떤 연관성이 있다고 생각되는 변수들이다.
예를 들어, 알츠하이머성 치매 발병 여부를 종속변수라고 했을 때, 치매 발병과 관계가 있는 것으로 생각되는 변수들은 나이, 성별, 아밀로이드 베타 단백질 침착량 등이 고정효과가 될 것이다.
그럼 Random effect (랜덤효과) 는 무엇일까?
흔히(?) 보는 랜덤효과에 대한 설명으로는 cluster (=군집) 라고 하는데, 나에게는 그렇게 직관적인 설명으로 느껴지지 않는다.
그럼 이번엔 cluster (군집) 의 개념에 대해 살짝 짚어보고 갈 필요가 있겠다.
군집이란 비슷한 or 연관된 속성을 가진 개체를 그룹화한 것을 뜻한다.
예를 들면 마케팅에서 비슷한 소비 성향을 가진 소비자들을 군집으로 묶어 맞춤 마케팅 전략을 세울 수 있는데, 성별과 연령, 주거지역, 직업 등에 따라 비슷한 성향의 소비자들을 군집으로 묶는 것이다.
그래서 랜덤 효과는 군집이다. 라는 설명이 나오는데, 솔직히 이게 더 혼란스럽게 만든다.
심지어 통계 책에 따라 랜덤효과를 제각기 설명해두기 때문에 더 혼란스럽다. 🤨
따라서 Gelman & Hill (2007) 이 발췌하여 정리한 fixed & random effect 의 개념들을 정리해보고자 한다.
📖 Gelman & Hill (2007)
1. Kreft & De Leeuw (1998)
- Fixed effect : 모든 individual에 걸쳐 constant 하다. - Random effect : 모든 individual 에 따라 달라진다. ⇨ 랜덤 intercept ɑᵢ 와 고정 slope β 는 각 individual i에 대해 평행한 선을 가지게 된다.
2. Searle, Casella, and McCulloch (1992)
- Fixed : Effects are fixed if they are interesting in themselves. - Random : Effects are random if there is interest in the underlying population.
3. Green & Tukey (1960)
- Fixed : 샘플이 모집단을 대표할 수 있을 때, corresponding variable 은 고정. - Random : 샘플이 모집단의 small part 일 때, corresponding variable 은 랜덤.
4. LaMotte (1983)
- Fixed : 아래 랜덤 효과의 경우가 아닐 때 - Random : 어떤 효과가 랜덤 변수로부터의 'realized value'라고 추정될 때, 그게 랜덤 효과. *참고로, 여기에서 realized value 라는 것은, 예를 들어 6면체의 주사위를 던진다고 할 때, 랜덤 변수는 경우의 수인 (1,2,3,4,5,6) 이고, 실제 주사위를 던져서 나온 값이 3이라면, realized value는 3인 것이다.
5. Robinson (1991), Snijders & Bosker (1999)
- Fixed : least squares (최소 제곱) 또는 maximum likelihood 를 이용해서 추정되었다면 고정 효과. - Random : Shrinkage 로 추정되었다면 랜덤 효과.
자, 그럼 여기까지 위 다섯 개의 고정효과 및 랜덤효과에 대한 정의가 모두 이해 되신 분 있나요?
솔직히 위 다섯 개 정의 모두 좀 ambiguous 한데.. Gelman & Hill (2007) 은 위 정의들에 대해 다음과 같은 견해를 보였다.
1. 첫 번째 정의는 다른 네 가지 정의와는 구별되는 점이 있다.
2. 두 번째 정의의 문제점은, 데이터나 디자인이 바뀌지 않았더라도, 해석의 목적을 달리하면 고정효과가 랜덤효과가 되기도 하고, 랜덤효과가 고정효과가 되기도 한다는 점이다.
3. 세 번째 정의는 유한한 모집단을 정의했다는 점에서 다른 네 가지 정의와 다르다. (그런데, 모집단에서 small 샘플이 아니고, 모집단의 모든 특성을 갖고 있지 않은 large 샘플이라면 어떻게 정의할 것인지? 에 대한 답은 없다.)
4. 네 번째 정의는 actual population에 대한 레퍼런스가 없다는 문제가 있다.
5. 주어진 효과가 고정인지 랜덤인지로 간주해야 하는지 unclear 하다는 문제가 있지만, 수학적 정확성이 있다.
Gelman & Hill (2007) 는 "fixed" 이니 "random" 이란 용어는 피하고, 모델 그 자체를 설명하는 편을 추천하였다.
그런데 저렇게 말하면.. 뭐 어쩌라는건지.. 라는 생각밖에..
그래서! 저자들은 다음과 같은 세 가지의 motivation을 서술해서 어떤 식으로 GLMM을 설명하면 좋을지에 대해 설명해주었다. 지금껏 꽤 ambiguous한 효과의 정의보다 저자들이 말하는 다음 세 가지를 중점적으로 살펴보는 것이 더 이해에 큰 도움이 될 것이다.
1. Accounting for individual- and group-level variation in estimating group-level regression coefficients.
2. Modeling variation among individual-level regression coefficients.
3. Estimating regression coefficients for particular groups.
특히 보건통계를 할 때, age나 sex와 같은 변수들을 '보정(control)' 한다는 목적으로 많이 사용하고는 한다.
그러나 ANCOVA는 단순히 보정을 위해 사용하는 모델링 기법이 아니다.
그런데 지금도 아주 많은 논문에서 ANCOVA를 linear regression 기법의 한 종류로 보면서, age와 sex 보정을 위해 사용한다고 보고한다.
따라서 ANCOVA가 잘못 사용된 예시를 찾는 것은 전-혀 어려운 일이 아니다.
NEJM이나 JAMA 저널에서 ANCOVA와 control을 검색하면 잘못된 논문을 찾는 것은 일도 아니다.
아무튼 따라서 ANCOVA의 오용에 대해서 한 번 살펴 봐야겠다는 생각이 들어,
Miller & Chapman (2001)의 논문인 "Misunderstanding Analysis of Covariance" 를 리뷰해보도록 하겠다.
벌써 이 논문이 publish 된 지 20년이 넘었는데, 아직도 ANCOVA가 저렇게 오용된다니..
위 논문에서 제시한 예시를 들어보도록 하겠다.
-3학년과 4학년 사이에 농구 퍼포먼스에 대한 차이가 있는지 모델링을 해보고 싶다고 하자.
농구 퍼포먼스를 종속변수로,
age를 potential covariate으로,
학년을 grouping variable로 모형을 적합하려고 한다.
농구퍼포먼스 ~ age+ 학년
여기에서 ANCOVA를 적합하는 목적은 학년에 따른 퍼포먼스의 차이가 있음을 증명하고, 그것이 age에 의한 차이가 아님을 말하고 싶기 때문이다.
근데 생각해보면.. 나이와 학년은 선형적인 관계를 갖고 있지 않나?
나이가 많을수록 학년은 높을 것이고, 나이가 어릴수록 학년은 낮을 것이다.
바로 이게 문제이다!
이 모델에서 Age를 공변량으로 넣으면 나이와 연관된 농구실력의 variance가 제거가 되고, age는 학년과 매우 상관관계가 높기 때문에 학년과 연관된 variance가 상당히 제거될 것이다.
따라서 이 모형의 ANCOVA 결과는 매우 의미가 없게 된다.
Covariate으로 인해 관심 있는 두 그룹 변수(독립변수)의 variance를 크게 제거하게 되면,
독립 변수에 covariate보다 구조적으로 이미 존재하는 difference가 있을 때, 문제가 발생할 수 있다.
이 때 covariate은 이러한 구조적인 differences를 그대로 두기 때문에, treatment effect 추정에 bias가 생길 수 있다. 이런 오류를 specification error라 한다.
Nonrandom Group Assignment
임상시험에서 치료군과 대조군을 정한다고 하자.
두 군에 속할 사람들을 정할 때, nonrandomly하게 정한다면 치료 전에 이미 존재했던 차이가 random error에서 오는지, 혹은 true group difference에 의해서 오는지 알 수가 없다.
이 문제는 treatment effects에 대한 해석을 어렵게 한다.
왜냐하면, 치료의 주 효과(main effect)가 ①treatment effect 및 pre-treatment의 interaction에서 오는지, 아니면 ②치료와 pre-treatment의 miningful overlap(variance shared)에 의해서 오는지 알 수 없기 때문이다.
"Pre-treatment 차이"와 "그룹 factor"의 overlap에 대한 잘못된 해석은 많은 경우 무시된다.
pre-existing group difference는 psychopathology 연구에서 매우 흔하게 발생한다고 한다.
Understanding Analysis of Covariance
ANCOVA는 ANOVA의 한 종류로 보면 된다.
ANCOVA는 독립변수 테스트의 파워를 개선하기 위해 개발된 것이지, 그 어떤 것을 "control"할 목적으로 생긴 것이 아니다.
ANOVA와 ANCOVA를 multiple regression and correlation(=MRC)의 framework 으로, 또한 General Linear Model(=GLM)로 이해하면 더 접근이 쉬울 것이다.
ANCOVA를 MRC의 context에 놓고, ANCOVA의 covariate을 regression predictor로 보는 연구들이 있다.
그런데 보통은 이러한 시각의 연구들 보다는 다른 쪽으로 이해하려는 것이 더 흔하다.
ANCOVA를 두 모델의 오차제곱합을 비교함으로써 그룹의 주효과를 테스트할 수 있다고 본다.
아래 두 모델을 살펴보자.
Yij=μ+αj+βXij+ϵij
Yij=μ+βXij+ϵij
Yij
= j번째 그룹의 i번째 subject의 dependent variable
Yij = j번째 그룹의 i번째 subject의 dependent variable
μ = grand mean
αj = j번째 그룹의 treatment effect
βXij = population regression coefficient, j번째 그룹의 i번째 subject에 대한 covariate score