Regression model을 만들다 보면, 독립변수로 명목형 변수를 사용할 때가 많다. 지역이나 성별, biomaker유/무 등이 대표적으로 많이 사용되는 명목형 변수로, 특히 medical 저널에서는 성별을 covariate으로 취급하여 성별에 따른 종속변수의 차이를 보고자 할 때가 많다.
명목형 변수들은 Dummy Variable로 바꾸어서 regression model을 만드는데, one hot 인코딩 방식으로 더미 변수들을 만든다.
예를 들면,
❕ male=0, female=1
❕ Biomarker유=1, Biomarker무=0
이런식으로 만든다.
이와 같은 binary 데이터들은 더미 변수로 만드는 것도 쉽고 큰 문제가 되지 않는다.
one-hot encoding의 이유는, 0과 1 대신 빨간색, 녹색, 파란색을 1,2,3 으로 코딩해버리면, 적합한 모델은 숫자가 더 큰 3을 빨간색보다 더 중요한 인자로 생각하게 되기 때문이다. 학력처럼 순서형이면 각 숫자에 의미가 있지만 여러 컬러처럼 단순 명목형일 때에는 one-hot 인코딩을 해야한다.
(단, 컬러가 연함 - 진함과 같이 순서형이라면 굳이 one-hot 인코딩을 안해도 된다.)
one-hot encoding의 예시는 아래 세 가지 카테고리로 보면 더 명확하게 이해가 된다.
그럼 binary 말고 여러 카테고리가 있는 변수의 경우는 어떤 식으로 더미 변수를 만들까?
Regression 모델을 만들 때에는 k개의 카테고리가 있다면, k-1개의 더미변수를 생성하게 된다. 위 그림에서 Blue일 때, d1, d2, d3 모두 0으로 코딩해도 Red, Green과 차이가 있으므로, d1과 d2만 만들어도 무방하다는 의미이다. 즉, d1과 d2가 0일 때, Blue가 되는 것이다.
이것도 예를 들어 보면 쉽게 이해가 되는데,
명목형 변수 중에 지역이나 부서 같은 여러 카테고리가 있는 변수를 생각해보자.
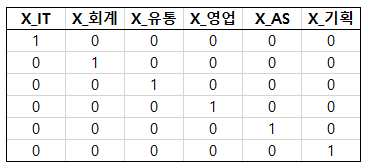
IT부서, 회계부서, 유통부서, 영업부서, AS부서, 기획부서 이렇게 6개의 부서가 있다고 하자.
그럼 총 6개의 카테고리를 다음과 같이 one-hot encoding 할 수 있다.
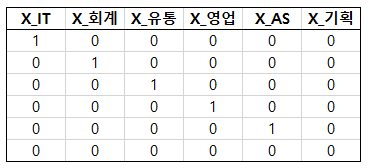
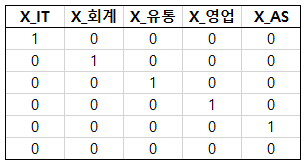
그런데 앞서 언급했듯이 카테고리가 6개라면, 더미 변수는 5개만 있어도 상관없다. 맨 마지막 기획부서를 전부 0으로 해도 무방하기 때문에 모델 적합의 편의성을 위해 맨 마지막 X_기획을 0으로 코딩하면 다음과 같다.
이는 또 다음과 같이 만들 수 있다.
그럼 굳이 왜 이와 같이 인코딩을 해주는 것일까?
'그냥 카테고리마다 1로 해주면 되지 않을까?' 라는 생각이 드는데, 굳이 이와 같이 코딩을 해주는 이유는 multicollinearity 때문이다. 다중공선성은 독립변수 간의 상관계수가 높을 때 발생하는데, 독립변수 A와 독립변수 B의 상관성이 높다면 A를 통해서 B도 추측이 가능하기 때문에 regression 모델의 회귀계수 해석에 어려움이 생긴다.