반응형
효과크기를 논하기 전에 P-value = 유의확률에 대해 언급하지 않을 수 없다.
어떤 통계적인 결론을 내릴 때 가장 많이 사용되는 지표인데,
정말 통계를 배우면서 지겹도록(?) 많이 나오고, 많이 사용된다.
효과 크기를 주제로 삼았는데, 왜 유의확률 이야기를 먼저 꺼내냐면..
통계검정을 할 때, 유의확률을 너무도 절대적인 기준으로 삼을 때, 검정 결과 해석에 오류가 있을 수 있기 때문이다.
생각보다 의학•보건 저널에서 이러한 p-value의 오류는 매우 매우 많이 보인다.
📖 예를 들어보자.
1. 도쿄 사람들의 평균 키가 런던 사람들의 평균 키보다 유의미하게 다른지 통계적으로 검정하고 싶어
각 두 도시에서 표본을 추출하여 t-test를 실시했다.
그 결과 p-value 가 0.01로 나와 두 도시 사람들의 키는 유의미하게 다르다고 결론을 내렸다.
마찬가지로,
2. 베를린 사람들의 평균 키가 파리 사람들의 평균 키보다 유의미하게 다른지 통계적으로 검정하기 위해
두 도시에서 표본을 추출하여 t-test를 실시했다.
그 결과 p-value 가 0.001로 나와 두 도시 사람들의 키는 유의미하게 다르다고 결론을 내렸다.
❓그럼 여기서 생각해보자.
'도쿄-런던' 사람들의 키 차이에 대한 p-value는 0.01, '베를린-파리' 사람들의 키 차이에 대한 p-value는 0.001이다.
⇨ "베를린-파리 사람들의 키 차이에 대한 p-value가 더 작으니까 이 두 도시 사람들의 키 차이가 '도쿄-런던' 도시 사람들의 키 차이보다 더 크겠군" 이라고 해석 할 수 있을까?
(당연히 안 되니까 이런 질문을 했겠지)
여기에서 P-value의 역할은
'도쿄-런던' 사람들의 키 차이가 통계적으로 유의미하게 다르다는 것, '베를린-파리' 사람들의 키 차이가 통계적으로 유의미하게 다르다는 것에서 끝나야 한다.
P-value가 더 작다고 해서 그것이 더 큰 차이가 있다는 정보를 주지 않음을 항상 염두에 두어야 한다.
다시 말하면, P-value가 더 작다고 해서 그것이 귀무가설이 얼마나 잘 못 되었는지가 아니라는 것이다.
따라서 "베를린-파리 사람들의 키 차이에 대한 p-value가 더 작으니까 이 두 도시 사람들의 키 차이가 '도쿄-런던' 도시 사람들의 키 차이보다 더 크겠군" 이라고 해석 할 수 있을까? 에 대한 대답은..
⇨ "당연히 이렇게 해석하면 안 된다." 이다.
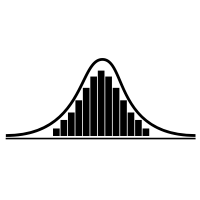
P-value의 개념을 다시 한 번 짚어보면..
유의확률은 '귀무가설 하에서' 통계량을 관측할 확률이다.
이는 아래 그림에서도 잘 표현이 된다.

위 키 차이에 대한 예시를 다시 한 번 살펴보면,
1) '도쿄-런던' 사람들의 평균 키 차이는 10cm, 이에 대한 p-value는 0.01,
2) '베를린-파리' 사람들의 평균 키 차이는 5cm, 이에 대한 p-value는 0.001 라고 할 때,
"귀무가설(Null hypothesis) = 두 도시 사람들의 키 차이는 없다." 이므로
'도쿄-런던' 사람들의 평균 키 차이는 10cm, 유의확률이 0.01이라는 의미는
⇨ "두 도시 사람들의 키 차이가 없는 것이 사실이라고 했을 때,
평균 키 차이가 10cm 가 관측될 확률이 0.01" 이라는 의미이다.
마찬가지로,
'베를린-파리' 사람들의 평균 키 차이는 5cm, 유의확률이 0.001이라는 것은
⇨ "두 도시 사람들의 키 차이가 없는 것이 사실이라고 했을 때,
평균 키 차이가 5cm 가 관측될 확률이 0.001" 이라는 의미이다.
따라서 더 작은 유의확률이라고 해서 그것이 더 큰 차이를 의미하는 것이 아님을 위 예시에서 살펴보았다.
그럼 이러한 차이를 보여주는 통계량이 있을까?
(있으니까 물어봤겠지)
당연히 있다!
그것이 바로 <Effect Size = 효과 크기>인데, 여기에서 너무 말이 길어져서 다음 글에서 이어서 살펴보도록 하겠다.
여기에서는 일단 <p-value가 더 작음 ≠ 더 큰 차이> 를 명확하게 짚고, 앞으로 p-value를 해석할 때 유의하도록!
반응형
'STATISTICS' 카테고리의 다른 글
| 다중비교 (Multiple comparisons test) [1] (0) | 2023.02.01 |
|---|---|
| Effect size : 효과 크기와 유의확률 (p-value) (2) (0) | 2022.12.25 |
| Two-sample independent t-test (독립 이표본 검정을 위한 가정들에 대한 논쟁) (0) | 2022.10.09 |
| 수리통계학 - 이산형 확률변수의 확률분포 (1) | 2022.10.08 |
| 수리통계학 - 이항분포의 정규근사 (0) | 2022.10.08 |